Technology
The following diagram provides an overview of the SerenityGPT architecture.
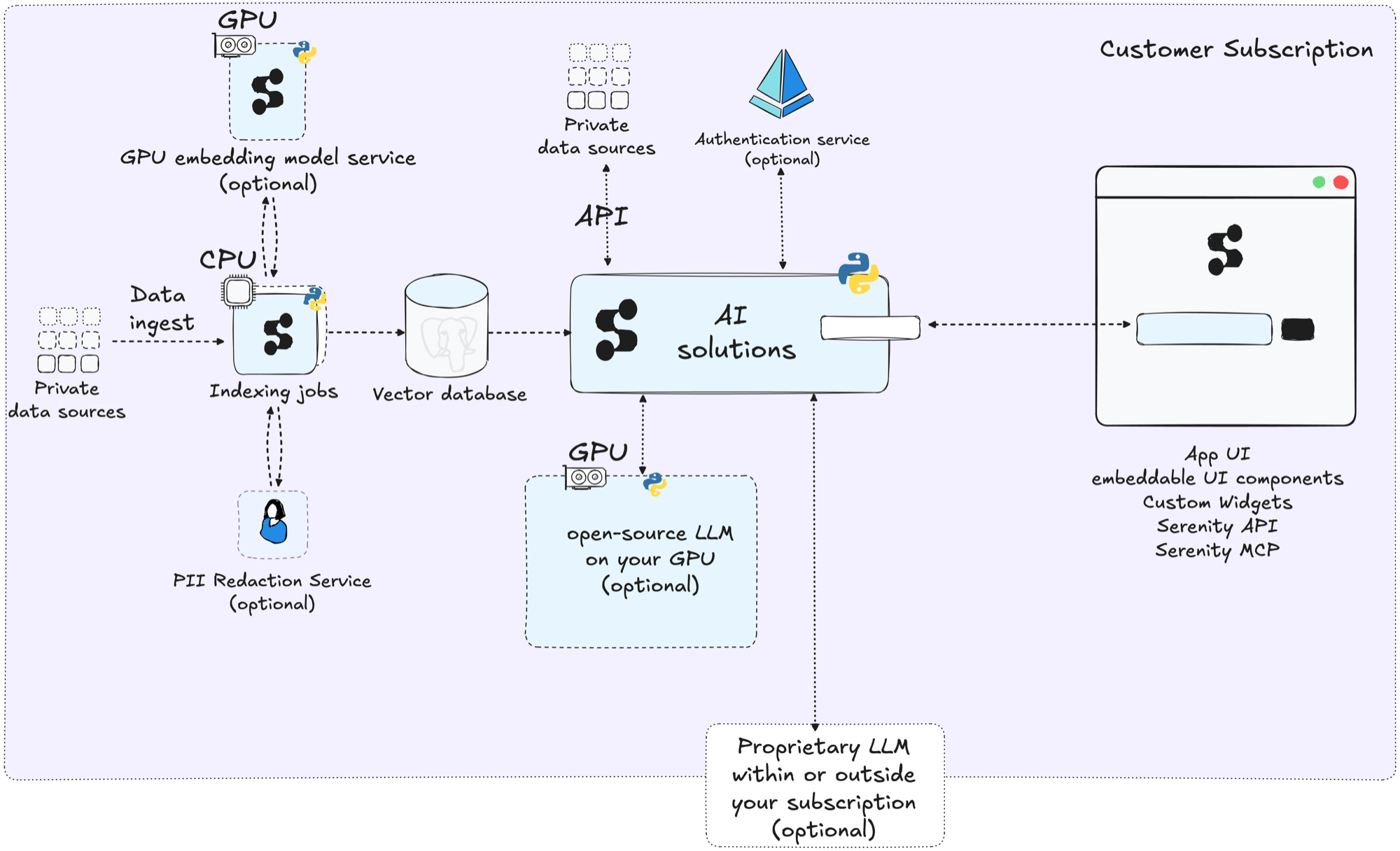
This page describes the technical capabilities that underpin SerenityGPT across all use cases.
Retrieval design
SerenityGPT uses retrieval-augmented generation (RAG) to ground every response in the customer's own data. The retrieval pipeline has several configurable stages:
- Embedding model selection. The platform supports multiple embedding models and providers. The model, chunking strategy, and retrieval parameters can be tuned per data source and use case.
- Chunking and metadata. During indexing, documents are split into chunks. Each chunk carries metadata such as source URL, document title, breadcrumbs, and custom fields defined in configuration. This metadata enables filtering and improves retrieval precision.
- Domain jargon handling. A synonyms map can be defined in configuration so that domain-specific terms, abbreviations, and alternative spellings are expanded during search.
- Hybrid retrieval. Queries run against both keyword and semantic (vector) search indexes. Combining the two methods improves recall for exact terms while preserving the semantic understanding of natural language queries.
- Result tuning. The number of search results passed to the LLM is configurable. Adjusting this parameter balances answer completeness against prompt length and latency.
- Prompt construction. The system prompt sent to the LLM is built from configurable templates with separate sections for role, tool instructions, and rules. Few-shot examples and language settings further shape the response.
Tool calling
SerenityGPT supports LLM tool calling for automating repeatable tasks and multi-step workflows. Tools are Python functions with typed arguments and descriptive docstrings. The LLM decides when to invoke a tool based on the user query and the tool descriptions provided in the prompt.
Built-in tools include document search and web search. Custom tools can be added in configuration by pointing to a Python module. This enables workflows where the LLM chains multiple tool calls together, makes decisions based on documented rules, and looks up information from internal or external sources.
Expandability
The platform is configured through a single YAML file that defines tenants, data sources, search behavior, prompt templates, and tools. This design supports several patterns:
- Multi-tenant isolation. Each tenant has its own data sources, search configuration, and prompt settings. Adding a new use case means adding a new tenant block, not deploying a new instance.
- Reusable data sources. All ingested data is available for reuse across tenants. A tenant can combine local and remote search to query documents from other tenants or other SerenityGPT instances without duplicating data.
- Custom data sources. Beyond the built-in connectors, any data source can be integrated by implementing a custom connector, which we do within hours.
Evaluation
SerenityGPT includes an automatic evaluation system that measures AI performance per use case and dataset. The system uses two complementary methods:
- URL verification. For questions with a known reference document, the system checks whether the response used the correct source.
- LLM-as-a-judge. For questions with answer instructions, a separate LLM call evaluates whether the response conforms to the criteria. See Running evals.
Over 50 golden sets have been curated across use cases and datasets. Each eval can include follow-up questions, filters, and expected-failure markers. Eval results integrate into CI/CD pipelines so that regressions block deployment. Statistical tests quantify whether changes are significant across large eval sets. An eval server aggregates results over time and provides a comparison view across runs.
Local LLM support
For deployments that require all processing to remain on-premises, a locally hosted model can serve as the LLM backend. The provider and model name are specified in configuration, making it straightforward to switch between providers or evaluate new models.
We advise on the best model to use and the optimal hardware configuration.
Monitoring and observability
SerenityGPT provides an admin UI that makes it easy to see which decisions AI made at each step and which data was available.
A telemetry service collects operational metrics and reports them to the central server.
Automated heath checks triggers alerts as soon as the system goes down.
UI integrations
SerenityGPT provides multiple integration paths for end users:
- Embeddable widget. A JavaScript component that can be added to any web page with a few lines of HTML. The widget supports chat and question-answer modes, popup and inline display, custom styling through CSS variables, and label customization. See Embedding SerenityGPT Widget component.
- REST API. A documented API for question answering, document management, and search. See API reference.
- MCP server. An MCP-compatible server that exposes SerenityGPT tools to clients such as Cursor and VS Code. See MCP server.
Staying current
SerenityGPT's sole focus is enterprise AI. The platform is built for rapid evaluation and adoption of the latest models, techniques, and tools. The evaluation system described above makes it possible to benchmark new models and retrieval strategies against existing golden sets before rolling changes into production.