SerenityGPT architecture overview
SerenityGPT is an advanced enterprise search and support solution that leverages natural language processing to provide accurate, context-aware search results across your organization's data sources. This document provides an overview of the SerenityGPT architecture and its key components.
Core components
SerenityGPT's architecture consists of several key components that work together to provide a comprehensive enterprise search solution. These components are designed to handle various aspects of data processing, search functionality, and user interaction. The following diagram illustrates the main components and their features:
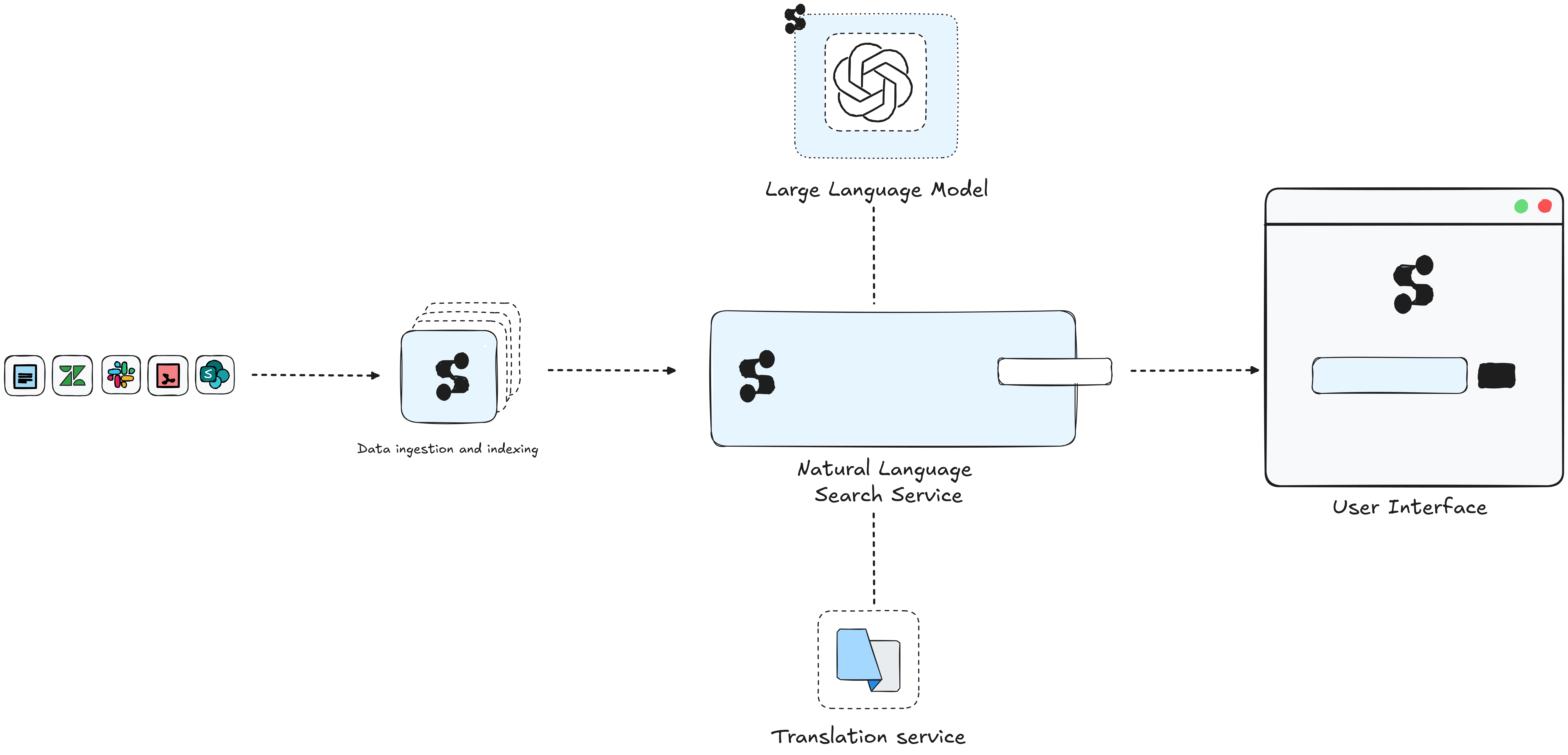
- Natural language search engine: Processes user queries and searches across indexed data sources.
- Data ingestion and indexing: Integrates with existing data sources to create a searchable index.
- AI response renerator: Utilizes large language models to phrase answers based on search results (optional).
- Multi-language support: Integrates with translation services for global deployments (optional).
- User interface: Web-based interface for query input and result display.
Deployment models
SerenityGPT offers flexible deployment options to accommodate different organizational needs, preferences, and security requirements. The two primary deployment models ensure that organizations can choose the most suitable approach for their infrastructure and management preferences:
- Internal Customer Subscription Deployment: Deployed entirely within the customer's infrastructure.
- External SerenityGPT Subscription Managed Deployment: Hosted and managed by SerenityGPT.
For detailed information on each deployment model, refer to the following documents:
Data flow
SerenityGPT involves two main data flows: search and indexing. Understanding these flows helps clarify how the system processes and retrieves information.
Search flow
- A user submits a query through the web interface or API.
- The Natural Language Search Engine processes the query.
- The search engine retrieves relevant information from the indexed data.
- (Optional) The AI Response Generator formulates a response based on the search results.
- The system returns results to the user interface for display.
Indexing flow
- New content is added to a monitored data source.
- Indexing jobs detect the new content.
- The system processes the content and generates embeddings.
- The indexed data and embeddings are stored and available for searches.
Security and data privacy considerations
SerenityGPT prioritizes data security and privacy through a comprehensive set of measures. These features protect sensitive information, ensure compliance with industry standards, and maintain user privacy:
- Integration with external authentication providers (e.g., Microsoft Entra ID).
- Optional PII redaction before using external AI services.
- Support for encryption of data in transit and at rest.
- Configurable data retention policies.
- TLS v1.3 implementation for secure communication.
- Compliance with data protection regulations where applicable (e.g., GDPR, CCPA).
For more detailed information on security and privacy measures, refer to the Security and Data Privacy and Secure Software Supply Chain documents.
System requirements
SerenityGPT is designed for enterprise scale, and the platform is not typically a performance or capacity bottleneck in most deployments. Nevertheless, proper system configuration ensures optimal performance, with the key considerations for sizing being memory and storage allocation for the database comoponent and memory allocation for the compute containers.
Requirements vary based on use case and data volume. For a good starting point as well as detailed information on system requirements, software dependencies, and compatibility, see the Server Requirements document.
These guidelines are starting points, and can be adjusted based on usage patterns and performance metrics. System requirements are typically determined through an interactive process:
- Deploy with baseline specifications.
- Monitor and analyze performance.
- Adjust based on usage patterns and performance metrics.
For the most accurate sizing recommendations, schedule a consultation with the SerenityGPT support team. The team will be able to analyze your requirements and usage patterns and provide customized recommendations to ensure optimal performance and resource utilization.
Next steps
- Review the specific deployment models:
- Internal Customer Subscription Deployment.
- External SerenityGPT Subscription Managed Deployment.
- Explore the Getting Started guide for implementation steps.
- Consult the Configuration Reference for detailed setup options.